
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- python
- 유데미부트캠프
- 코딩테스트
- 데이터드리븐
- 스타터스부트캠프
- 부트캠프후기
- 데이터프레임
- Leetcode
- numpy
- 데이터분석
- 넘파이
- Til
- matplotlb
- 태블로
- ndarray
- Tableau
- 브루트포스 알고리즘
- 그리디 알고리즘
- 유데미큐레이션
- 시각화
- 판다스
- DataFrame
- 백준
- 유데미코리아
- 파이썬
- 취업부트캠프
- pandas
- 데이터시각화
- 정렬
- 유데미
- Today
- Total
Diary, Data, IT
유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습 일지 본문

유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습 일지
5주차 학습내용
1. Tableau
1.1 애니메이션
- [페이지]에 컬럼을 지정하면 해당 컬럼에 따라 순차적으로 변하는 애니메이션 효과를 사용할 수 있음
- [주석추가] - [페이지 이름]을 통해 현재 애니메이션이 보여주는 정보를 표시할 수 있음
- [기록 표시]를 통해 지정한 특정 요인의 흐름에 따른 변화를 기록을 남겨가며 재생할 수 있음
1.2 세부 수준 계산(LOD)
- INCLUDE, EXCLUDE, FIXED 세 가지 방법으로 세부 수준 계산을 수행할 수 있음
- INCLUDE: 현재 지정된 세부성보다 더 깊은 세부성을 가지는 계산을 수행할 때 사용
ex) 주 단위의 그래프에 도시단위로 연산한 결과(더 세부적인 연산)를 보여주고 싶을 때
{INCLUDE [세부컬럼명]: 수행할 연산}
- EXCLUDE: 현재 지정된 세부성보다 더 낮은 세부성을 가지는 계산을 수행할 때 사용
현재 가장 세부적인 컬럼을 제외하면 그보다 위 세부성을 가지는 컬럼으로 이동하여 연산 적용
ex) 도시단위의 그래프에 주 단위로 연산한 결과(덜 세부적인 연산)를 보여주고 싶을 때
{EXCLUDE [제외할컬럼명]: 수행할 연산}
- 여러 층의 세부정보를 포함하거나 제외하고 싶을 때는 컬럼명에 ,를 사용하여 여러 개 지정할 수 있음
- FIXED: 사용할 세부정보를 절대경로로 지정해두고 고정하고 싶을 때 사용
ex) 어느 세부단위에서도 도시단위로 연산한 결과를 보여주고 싶을 때
{FIXED [Country], [State], [City]: 수행할 연산}

1.3 호주의 산업 분석

- 박스플롯을 통해 현재 가장 안정적이며 좋은 수익성을 올리고 있는 곳은 빅토리아 주임을 판단하고, 빅토리아 주가 의류 산업에 가장 적합한 도시라는 가설을 설정
- 실제로 지난 15년간 여러 주에서의 의류 산업 매출 현황을 살펴봤을 때, New South Wales와 Victoria 주에서 매출액이 꾸준히 증가하는 형태를 보이고 있었음. 하지만 이는 각 주의 인구 수 등 다른 요인을 전혀 고려하지 못한 그래프로, 단순히 인구 수가 증가하여 매출액도 증가한 것일 수 있음
- 인구 1인당 매출액을 그렸을 때 여전히 New South Wales와 Victoria 주에서 매출액이 증가하는 모습을 보였음. 또한 매출액의 증가 추세가 빅토리아 주가 더 가파르게 나타나 더 향후 성장 가능성이 높은 도시라는 결론을 내림
태블로 학습후기
- 기초를 거쳐 심화과정을 배우면서, 단순한 그래프를 그리는 반복적인 부분들은 어느정도 익숙해져서 어렵지 않게 다룰 수 있었다. 하지만 세부 수준 계산 파트에서 많은 어려움을 겪었다. 세부 수준을 지정할 수 있는 3가지 방법과, 지도에 보이는 것과 계산의 수준을 다르게 하여 값을 표기할 수 있다는 기본적인 내용은 이해했으나 FIXED 방법에 대한 이해가 명확하게 가지 않았다. 다음 주부터 오프라인 강의로 태블로를 배우면서 이 부분을 제대로 배울 필요가 있을 것 같다.
- 강의의 전체적인 구조가 한 챕터를 거치면서 하나의 데이터에 대해 대시보드를 완성하는 형식으로 진행되었다. 그리고 각 챕터의 마지막 강의에서는 전체적인 그래프의 해석을 다뤘는데, 강의를 통해 태블로를 통한 시각화 역량 이외에도 비즈니스에 적합한 대시보드를 작성하는 능력이나 그래프 해석 능력을 쌓을 수 있어서 좋았다. 하나의 그래프를 꽤 깊게 파고들어 하나하나 해석해주는 강의는 잘 없었던 것 같은데 너무 만족스러웠다 :)
2. Python 시계열 분석
2.1 ETS 분해
- ETS모델이란 계절성 요소, 잔차 요소, 추세 요소를 분해하여 요소를 더하거나 곱하거나, 일부를 사용하지 않고 평활화하는 모든 모델들을 지칭
- 덧셈 모델(additive model)은 추세가 선형에 가깝고, 계절성이 거의 일정해보일 때 적합
- 곱셈 모델(multiplicative model)은 비선형적으로 증가 혹은 감소하는 경우에 적합
- 객체.trend, 객체.seasonal, 객체.resid를 통해 각 추세 요소에 개별적으로 접근할 수 있다.
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(airline['Thousands of Passengers'], model = 'multiplicative')
result.plot(); # 추세, 계절, 잔차 요소로 분리한 결과
2.2 EWMA(지수평활법)
- 지수 가중 이동 평균을 통해 시계열 데이터의 특징을 잡아내고 예측하는 모델
- 최근의 값들에 더 높은 가중치를 적용하여 시차효과를 감소시킨다.
- 지수평활법에 사용되는 대표적인 가중치는 alpha(평활상수)가 있으며, span, c, halflife를 변형하여 alpha로 사용할 수 있다. (ex. alpha = 2/(span + 1))
2.3 홀트-윈터스 계절성 기법
- 이중/삼중 지수평활법
- 추세 요소 b_t, 계절 요소 s_t, 일반 요소 l_t
- 덧셈 기법과 곱셈 기법이 존재
- 홀트 기법: l_t와 b_t만 고려한 모델로 이중 지수평활법
- 윈터스 기법: 계절적인 요소까지 고려한 모델로 삼중 지수평활법 (L은 반복되는 주기)
df = pd.read_csv('../Data/airline_passengers.csv', index_col = 'Month', parse_dates = True)
df.index.freq = 'MS'
#train, test 분리
train_data = df.iloc[:109] # 1939년까지
test_data = df.iloc[108:]
#모델 생성
from statsmodels.tsa.holtwinters import ExponentialSmoothing
fitted_model = ExponentialSmoothing(train_data['Thousands of Passengers'],
trend = 'mul', seasonal = 'mul', seasonal_periods = 12).fit()
test_predictions = fitted_model.forecast(36) #예측하고자 하는 기간을 입력하고 예측
#실제 데이터와 예측 데이터를 그래프로 확인
train_data['Thousands of Passengers'].plot(legend = True, label = 'Train', figsize = (12, 8))
test_data['Thousands of Passengers'].plot(legend = True, label = 'Test')
test_predictions.plot(legend = True, label = 'PREDICTION')
2.4 ACF. PACF
- ACF는 자기상관관계, PACF는 부분 자기상관관계
- ACF는 시차에 따른 상관관계를 구한 것으로 X축에 시차를, Y축에 자기상관계수를 표현
- PACF는 전 시점의 잔차와 현재의 실제 값 사이의 상관관계를 구한 것
import statsmodels.api as sm
from statsmodels.tsa.stattools import acovf, acf, pacf, pacf_yw, pacf_ols
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(df1['Thousands of Passengers'], lags = 40); #lags: 몇 번쨰 시차까지 보여줄 것인지 선택
plot_pacf(df2, lags = 40, title = 'Daily Female Birts');
2.5 ARIMA
- AR: 자동회귀, I: 누적, MA: 이동평균, ARIMA(p,d,q)
- 차분을 통해 비정상성 제거, 계절성이 있을 경우 계절성을 반영한 차분 필요
- 정상성: 정상 시계열은 상수이며, 시간에 따른 평균과 분산(공분산)이 일정해야 함
- AR은 현재 시계열 값이 이전 시점 시계열 값들의 선형 결합과 백색 잡음의 합으로 이루어진 모형으로, 현재 또는 이전 데이터로부터 미래 데이터를 예측하기 위한 모델
- MA는 이전 항에서의 error들을 반영하여 현재를 예측하는 모델로, 과거 q개 이전의 변화율을 현재 시점에 반영하여 추세가 변하는 상황에서 적합
- ARIMA 모델에서 계절성을 포함한 모델을 SARIMA라고 하며, SARIMA에 시간, 예측하려는 변수 이외에도 추가적인 정보를 줄 수 있는 외생변수들을 추가할 수 있는데, 이를 SARIMAX 모델이라고 함
2.6 ARIMA 모델의 차수 선택
- PACF가 가파르게 감소하는 부분이 있다면 그 시기에서 AR(p) 사용
- PACF가 점진적으로 감소하다면 MA()를 사용해야 함
- ACF또한 마찬가지로 가파르게 감소하는 부분에서 MA(q)를 사용하고, 점진적으로 감소한다면 AR() 사용
- 차분이 필요한 모델의 경우, 차분을 진행하고 ACF, PACF 그래프를 다시 그려 추가적인 범위를 확인
- 하지만 현실적으로 패키지를 통한 격자 탐생을 수행하는 것이 훨씬 좋다.(AIC가 가장 작은 모델 반환)
##SARIMAX 모델 적합
#외생변수는 exogenous에 데이터프레임 형식으로 넣어줘야 함
auto_arima(df1['total'], exogenous=df1[['holiday']], seasonal = True, m = 7).summary()
#모델 적합 결과를 넣어 학습
model = SARIMAX(train['total'], exog = train[['holiday']], order = (1,0,0), seasonal_order = (1, 0, 1, 7),
enforce_invertibility = False)
results = model.fit()
results.summary()
#예측결과 반환
predictions = results.predict(start, end, exog = test[['holiday']]).rename('SARIMAX with Exog')
#시각화
ax = test['total'].plot(figsize = (12, 8), legend = True)
predictions.plot(legend = True)
for x in test.query('holiday==1').index:
ax.axvline(x=x, color='r', alpha = 0.5);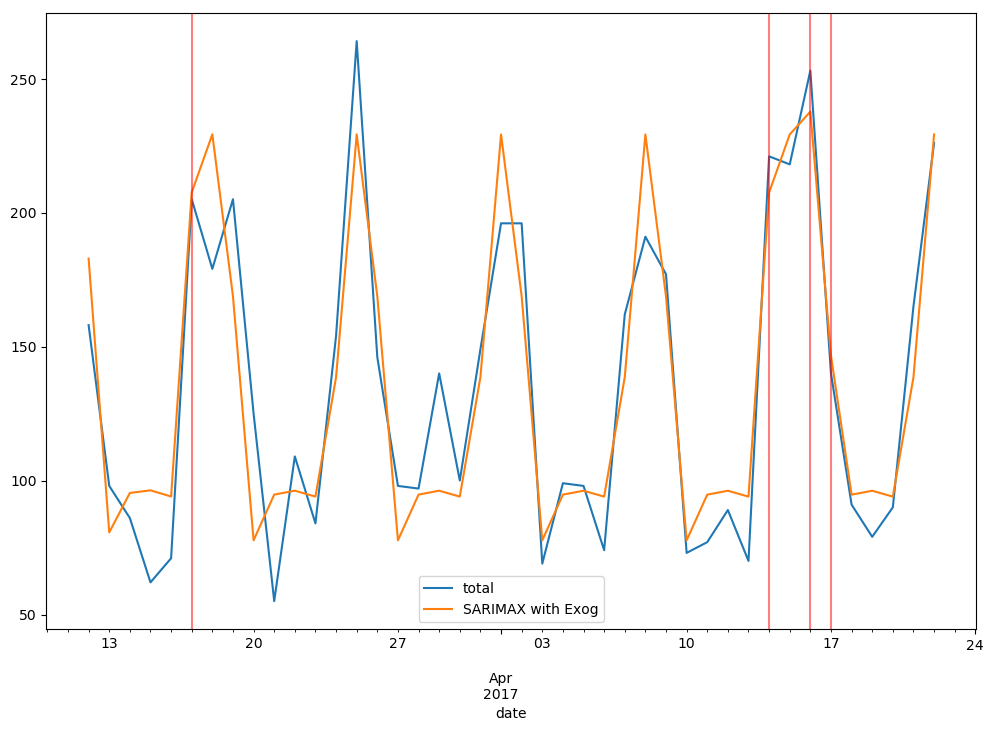
2.7 딥러닝 개요
- 입력이 주어질 때, 각각의 입력에 가중치를 곱하고 더한 값을 활성화 함수에 전달하여 출력하는 것이 기본적인 구조
- 출력이 항상 0이 되는 것을 막기 위해, bias(편향)을 더함
- 입력 레이어, 히든 레이어(은닉층), 출력 레이어로 구성되며 출력층에서는 원하는 결과값이 반환되어야 함
- epochs: 데이터 전체를 반복할 횟수, batch: 하나의 데이터를 작은 그룹으로 나누어서 학습하는데, 한 그룹에 들어갈 데이터 수
2.8 RNN(순환 신경망), LSTM
- RNN은 출력을 자기 자신에게 다시 보내서 출력이 같은 뉴런의 입력이 되는 모델로 시퀀스 데이터를 처리하여 다음 시점을 예측하는데 적합함
- RNN은 시간이 점차 흐르면서 처음의 입력이 잊혀져가는 문제가 있어 처음의 입력과 최근의 입력 사이의 균형을 맞춰 이 문제를 해결한 모델이 LSTM
- 입력은 이전 셀에서의 정보들과 현재 입력값, 출력값은 현재까지 셀 정보들과 현재 출력값
-> 이전의 입력값 중 버릴 부분을 선택하여 버리고, 가져갈 정보들을 취합하여 셀을 업데이트
-> 선택한 정보들을 사용해 현재 입력값에 대한 출력값을 내보냄 - GRU는 LSTM에서 입력 게이트와 망각을 합쳐서 하나로 만들고(업데이트 게이트). 셀 스테이트와 은닉층을 합친 모델로 LSTM보다 훨씬 간단한 모델
#### RNN 실습코드 ####
#데이터 스케일링(정규화)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train)
scaled_train = scaler.transform(train)
scaled_test = scaler.transform(test)
from keras.preprocessing.sequence import TimeseriesGenerator
#순환신경망에 넣을 형태로 데이터를 가공
n_input = 12 #계절성:12개 등 데이터의 특징에 맞는 수로 선택해야 함
n_features = 1 #사용할 변수의 수 - 시계열에서는 항상 1
TimeseriesGenerator(data, target, length=input할 데이터의 길이)
train_generator = TimeseriesGenerator(scaled_train, scaled_train, length = n_input, batch_size = 1)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
#은닉층이 없는 단순한 모델
model = Sequential()
model.add(LSTM(150, activation = 'relu', input_shape = (n_input, n_features)))
model.add(Dense(1))
model.compile(optimizer = 'adam', loss= 'mse')
model.fit_generator(train_generator, epochs = 25)
## test 예측
#1시점의 값을 제외하고 직전값에 예측값을 포함시켜가면서 순차적으로 예측하는 구조
test_predictions = []
first_eval_batch = scaled_train[-n_input:]
current_batch = first_eval_batch.reshape((1, n_input, n_features))
for i in range(len(test)):
current_pred = model.predict(current_batch)[0]
test_predictions.append(current_pred)
current_batch = np.append(current_batch[:,1:,:], [[current_pred]], axis = 1)
#스케일링 전 형태로 변환
true_predictions = scaler.inverse_transform(test_predictions)
test['Predictions'] = true_predictions
test.plot()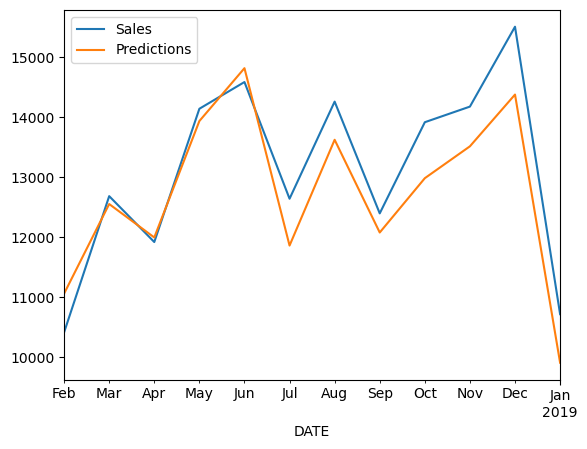
Python 시계열 분석 학습후기
- 전공으로 시계열 분석을 이미 들은 뒤에 수강했던 나에게는 적당한 난이도와 꼭 필요하지만 너무 어렵지는 않은 정도 깊이의 설명, 친절한 실습 코드와 다양한 성격의 예제 데이터를 다뤄볼 수 있는 적절하고 유용한 강의였던 것 같다. 이전에 배우면서는 파이썬으로 코드를 따로 작성하지는 않았었고, SAS를 통한 ARIMA 모델 적합 과정만 코드를 작성하면서 배웠는데 전체적인 과정을 실습해볼 수 있어서 좋았다. 또 ARIMA 모델 적합을 ACF, PACF 그래프와 뇌피셜을 섞어가며 하나씩 해보는 것이 아니라 자동화된 격자 탐색으로 한번에! 정확하게! 수행할 수 있다는 점이 너무 유용했다.
- 다만 마지막 딥러닝 파트에서 LSTM 개념 설명이 조금 어려웠다. 딥러닝 자체의 개념에 대한 학습은 했었지만 LSTM 모델 자체를 깊게 파고든 적은 없었어서 강의에서 설명해준 모델의 흐름 정도만 이해하고 가려고 노력했다. 조만간 딥러닝 쪽 개념을 한번 쭉 정리할 필요가 있을 것 같다는 생각이 들었다.
다음 주 보완사항
1. 유데미 스타터스 4기 필수 강의를 아직 다 듣지 못했다. 여유가 될 때마다 강의를 수강해서 2주 내에는 강의를 다 들을 수 있도록 열심히 해야할 것 같다 ㅠㅠ
2. 다음 주부터는 오프라인으로 태블로를 배우게 되는데, 매일 과제가 주어지는 것으로 알고있다. 조원 분들과 협동해서 과제를 잘 해결해나가는 것이 목표이다. 조별 점수를 많이 모아서 이번에는 상품도 받아가고 싶다!
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'STARTERS' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 7주차 학습 일지 (0) | 2023.03.26 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습 일지 (0) | 2023.03.19 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지 (0) | 2023.03.03 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 3주차 학습 일지 (0) | 2023.02.26 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 2주차 학습 일지 (1) | 2023.02.19 |



