
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 넘파이
- python
- ndarray
- 판다스
- 스타터스부트캠프
- 백준
- 태블로
- 유데미코리아
- 취업부트캠프
- matplotlb
- numpy
- 유데미부트캠프
- 데이터프레임
- 시각화
- Leetcode
- 그리디 알고리즘
- pandas
- DataFrame
- 브루트포스 알고리즘
- Til
- 유데미
- 코딩테스트
- 유데미큐레이션
- 데이터시각화
- 데이터드리븐
- 정렬
- 부트캠프후기
- 파이썬
- 데이터분석
- Tableau
- Today
- Total
Diary, Data, IT
[Python] Pandas 완전정복1 - DataFrame(데이터프레임) 본문
Pandas 완전정복1- DataFrame(데이터프레임)

0. Pandas란?
- 많은 양의 데이터를 로드해서 분석하는데 최적화된 패키지이며, 다양한 데이터 분석 함수를 제공합니다.
- Numpy를 내부적으로 활용하기 때문에 Numpy를 같이 로드해줘야 합니다.
- 다른 시스템에 쉽게 연결할 수 있어 활용도가 좋습니다.
1. Series와 DataFrame
Series는 pandas의 1차원 배열 자료구조입니다.
series = pd.Series([넣을 원소])를 이용하여 시리즈 데이터를 만들 수 있습니다.
DataFrame(데이터프레임)은 여러개의 Series가 모여서 이루는 2차원 배열 구조이며,
인덱스(index), 변수(column), 값(value)로 이루어진 데이터입니다.
데이터프레임에는 넘파이 라이브러리에서 지원하는 수학 및 통계 연산을 그대로 이용할 수 있습니다.
데이터프레임은 딕셔너리 자료에 데이터프레임으로 변환하는 메소드를 사용하여 만들 수 있습니다.
data = { 'key' : ['value']}
df = pd.DataFrame(data)
#Series 만들기
series = pd.Series([10, 20, 30, 40])
#DataFrame 만들기
data = { 'Name': ['S1', 'S2', 'S3'],
'Age': [25, 28, 22],
'Score': [95, 85, 75]}
df = pd.DataFrame(data)
df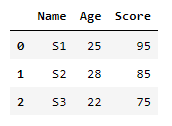
2. DataFrame 칼럼, 인덱스 지정
1) 인덱스 지정
인덱스는 데이터프레임을 생성하면서 지정해줄 수 있습니다.
pd.DataFrame의 index 옵션에 지정할 인덱스명을 리스트 형식으로 넣어서 지정할 수 있습니다.
pd.DataFrame(data, index = [인덱스명])
데이터프레임을 생성한 뒤에도 인덱스에 따로 접근할 수 있습니다.
df.index를 입력하면 인덱스명을 확인할 수 있으며, 위와 동일하게 인덱스명이 담긴 리스트를 지정해주면 인덱스가 변경됩니다.
df.index = [인덱스명]
2) 칼럼 지정
칼럼도 인덱스와 마찬가지로 데이터프레임을 생성한 뒤 따로 접근할 수 있습니다.
df.columns를 입력하면 칼럼명을 확인할 수 있으며, 칼럼명이 담긴 리스트를 지정해주면 칼럼명이 변경됩니다.
df.columns = [칼럼명]
#인덱스명 지정하기
df2 = pd.DataFrame(data, index = ['row1', 'row2', 'row3'])
#인덱스명, 칼럼명 변경하기
df2.index = ['row1', 'row2', 'row3']
df2.columns = ['col1', 'col2', 'col3']
df2
3. 데이터프레임 탐색
분석에 들어가기 전에 데이터프레임을 살펴보고 대략적인 정보를 얻을 수 있는 함수들은 여러가지가 있습니다.
df.head(n) #처음 n개의 행을 출력
df.tail(n) #마지막 n개의 행을 출력
df.info() #칼럼, 결측치 수, type 등 세부정보 확인
df.describe() #연속형 변수의 요약통계량 확인, include = 'all'옵션을 사용하면 범주형 변수도 출력
df.column.value_counts() #해당 칼럼에 각 값이 몇 개씩 존재하는지 출력
#데이터셋 불러오기
import seaborn as sns
df = sns.load_dataset('iris')
df.info() #데이터의 세부정보
df.describe() #요약통계
중복되지 않은 값을 확인하고 싶을 때는 unique 메소드를 사용합니다.
df.nunique() #각 칼럼별로 중복되지 않은 고유한 값이 몇 개씩 존재하는지 출력
df.column.unique() #해당 칼럼에 존재하는 고유한 값들을 출력
df.nunique #각 칼럼당 고유한 값이 몇개 존재하는지 확인
중복된 데이터를 찾고 싶을 때에는 duplicated 메소드를 사용합니다.
df.duplicated(subset = column)
#지정 칼럼의 값이 중복이면 True 반환, 지정하지 않으면 모든 칼럼의 값이 같은 행에 True 반환
df.drop_duplicates(subset = column)
#특정 칼럼의 중복 행(위에서 True로 표시된 행)을 모두 제거한 데이터 반환
df.duplicated(subset = 'sepal_width') #subset 칼럼의 값이 중복이면 True
결측치 수도 간단하게 확인할 수 있습니다.
df.isnull().sum() #각 칼럼의 결측치 수 반환
df.isnull().sum() #각 칼럼의 결측치 수 반환
4. 데이터프레임 값 추출 및 수정
1) 인덱스를 이용한 데이터프레임 접근
데이터프레임은 칼럼(열) 벡터가 기본이기 때문에 DataFrame[열][행] 순으로 접근하며,
각각 열이름과 행이름(인덱스명)을 적어 접근할 수 있습니다.
또한 칼럼은 DataFrame.칼럼명 으로도 접근할 수 있습니다.
하나의 값을 수정하려는 경우 기본 자료형(숫자, 문자 등)의 형태를 지정하며,
행이나 열을 모두 수정하려는 경우 필요한 값을 모두 담아 리스트 형태로 지정해줘야 합니다.
값에 직접 접근하여 수정하는 경우, 원본을 변경하는 것이므로 판다스에서 자체적으로 오류메세지를 출력하지만
값은 제대로 변경되는 것을 확인할 수 있습니다.
data = { 'Name': ['S1', 'S2', 'S3'],
'Age': [25, 28, 22],
'Score': [95, 85, 75]}
df1 = pd.DataFrame(data) #데이터프레임 생성
#값에 직접 접근하여 데이터 수정
df['Name'][0] = '김'
df['Name'][1] = '이'
df['Name'][2] = '박'
df
2) loc, iloc을 이용한 데이터프레임 접근
기본적으로 loc, iloc 메소드는 [행, 열] 순으로 데이터프레임에 접근합니다.
이 중 loc 메소드는 행과 열의 이름(label)을 기준으로 접근하고,
iloc 메소드는 인덱스를 기준으로 접근합니다.
df.loc[인덱스명, 칼럼명]
특히 loc메소드는 이름을 기준으로 접근하기 때문에 슬라이싱을 사용해도
기존 슬라이싱처럼 끝자리+1로 사용하지 않고 입력한 값 그대로를 반환합니다.
df1.loc[2] #하나만 적을 경우에는 행이 먼저이기 때문에 행으로 인식
df1.loc[1:2] #인덱스명이 1인 행과 2인 행 사이의 값들을 반환
df1.loc[2, 'Age'] #행 인덱스명이 2이고, 칼럼명이 'Age'인 값 반환
df1.loc[:, ['Age', 'Score']] #모든 행의 Age와 Score 값을 반환
df1.index = ['row1', 'row2', 'row3']
#인덱스 라벨을 새로 지정하고 loc을 사용하면 라벨을 기준으로 입력해야함
df1.loc['row3', ['Age', 'Score']] #행 인덱스명이 'row3'인 행의 Age와 Score값을 반환
df.iloc[인덱스번호, 칼럼 인덱스번호]
인덱스 번호는 0부터 시작하며 슬라이싱을 사용할 경우 기존처럼 [시작번호:끝번호+1]을 입력해줘야 합니다.
df1.iloc[1:3] #iloc은 시작점:끝점+1로 동작, 1-2번째 행을 반환
df1.iloc[2, [2, 0]] #2번째 행의 2번째 0번째 칼럼의 값 반환
df1.iloc[:, [2, 0]] #모든 행의 2번째 0번째 칼럼의 값 반환
3) 행, 열 추가하기
행을 추가하기 위해서는 특정 행에 접근한 뒤 행에 들어갈 값을 리스트로 넣어주면 됩니다.
df.iloc[행 인덱스 번호] = [들어갈 원소 리스트] #행 추가하기
#새로운 데이터프레임 생성
data = {'Sex': ['Male', 'Female', 'Male'],
'Age': [25, 28, 22],
'Score': [95, 85, 75]}
df2 = pd.DataFrame(data)
#행 추가하기
df2.loc[3] = ['M', '20', 100]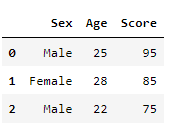
열을 추가하기 위해서는 새로 만들 칼럼명을 입력하고 칼럼에 들어갈 값을 리스트로 넣어주면 됩니다.
df[새로 만들 칼럼명] = [들어갈 원소 리스트] #열 추가하기
기존의 칼럼을 이용해 새로운 칼럼(파생변수)을 만들 수도 있습니다.
df[새로 만들 칼럼명] = df[기존 칼럼명] + 연산
#열 추가하기
df2['Age2'] = df2['Age'] + 1 #기존 칼럼을 이용해 새로운 칼럼을 만들 수도 있다.
df2['Score/Age'] = round(df2['Score'] / df2['Age'])
4) 특정 조건에 맞는 행, 열 출력
불린 인덱싱을 사용하여 인덱스 안에 조건을 넣어주면 True인 부분만 찾을 수 있습니다.
df[True, False를 반환하는 조건문]
df = sns.load_dataset('iris')
#1. 종류가 setosa인 행만 출력
df[df['species'] == 'setosa']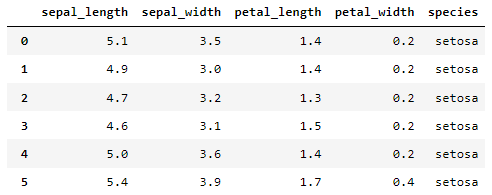
#2. petal_length가 6이상인 행의 종만 출력 - loc이용
df.loc[df['petal_length'] >= 6, 'species']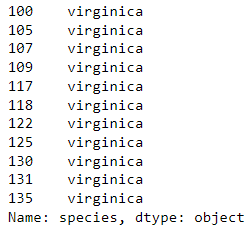
다중 조건을 사용할 경우에는 조건 사이에 &, |, ~을 조합해서 넣어줘야하며, 조건 사이에는 괄호를 닫아줘야 합니다.
#3. patal_length가 6이상이고 petal_width가 1이상인 행 출력
df[(df['petal_length'] >= 6) & (df['petal_width'] >= 1)]
불린 인덱싱과 loc 메소드를 사용하여 조건에 따라 다른 값을 부여하는 새로운 칼럼을 생성할 수 있습니다.
#4. 종이 setosa = 1, versicolor = 2, virginica = 3으로 하는 species_number 칼럼 생성
df.loc[df['species'] == 'setosa', 'species_number'] = 1
df.loc[df['species'] == 'versicolor', 'species_number'] = 2
df.loc[df['species'] == 'virginica', 'species_number'] = 3
5) 특정 값을 새로운 값으로 변경하기
데이터프레임에 속한 특정 값들을 새로운 값으로 일괄적으로 변경해주기 위해서는 replace 메소드를 사용합니다.
df.replace([기존 값들], [새로운 값들], inplace = True)
이 때 inplace = True 옵션을 지정하면 원본 데이터를 바로 수정해줍니다.
data = { 'Sex': ['Male', 'Female', 'Male'],
'Age': [25, 28, 22],
'Score': [95, 85, 75]}
df2 = pd.DataFrame(data)
#Male을 M으로 Female을 F로 변경하기
df2.replace(['Male', 'Female'], ['M', 'F'], inplace = True)
#데이터프레임.replace([전], [후], inplace = True)
#inplace = True 메소드는 원본을 변경하여 저장하도록 해줌
'Python' 카테고리의 다른 글
| [Python] 데이터 시각화 - Seaborn (0) | 2022.08.03 |
|---|---|
| [Python] 데이터 시각화 - Matplotlib (0) | 2022.08.03 |
| [Python] Numpy 완전정복2 - 연산, 벡터, 무작위, 수정 (0) | 2022.07.29 |
| [Python] Numpy 완전정복1 - ndarray 기초 (0) | 2022.07.28 |



