
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 파이썬
- 판다스
- 유데미코리아
- 정렬
- 데이터시각화
- 유데미
- DataFrame
- 브루트포스 알고리즘
- 그리디 알고리즘
- 데이터프레임
- 부트캠프후기
- 스타터스부트캠프
- 유데미부트캠프
- 데이터분석
- 넘파이
- 태블로
- Til
- python
- pandas
- 취업부트캠프
- 시각화
- 코딩테스트
- 데이터드리븐
- ndarray
- Leetcode
- numpy
- Tableau
- 백준
- matplotlb
- 유데미큐레이션
- Today
- Total
Diary, Data, IT
[TIL] 6일차 TIL(20230213) - 데이터 시각화 및 활용 본문

[TIL] 6일차 TIL(20230213) - 데이터 시각화 및 활용
1. 그래프 꾸미기 옵션
1.1 수평선, 수직선
- plt.axhline(y좌표, x축시작위치, x축끝위치): 수평선 그리기, 전체를 1이라고 했을 때의 상대적인 위치를 지정
plt.hlines(y좌표, x축시작좌표, x축끝좌표)
- plt.axvline(x좌표, y축시작위치, y축끝위치): 수직선 그리기, 전체를 1이라고 했을 때의 상대적인 위치를 지정
plt.vlines(x좌표, y축시작좌표, y축끝좌표)
1.2 텍스트, 화살표 그리기
- plt.text(x좌표, y좌표, 텍스트)
ha: 텍스트 박스의 수평 옵션(left, center, right)/va: 텍스트 박스의 수직 옵션(bottom, center, top)
bbox = {'boxstyle': round/square, 'fc':facecolor, 'ec':edgecolor, ...}: 텍스트 박스의 구체적인 옵션 지정
- plt.annotate('텍스트', xy=(화살표x,화살표y), xytext=(텍스트x,텍스트y), arrowprops=화살표속성(딕셔너리))
화살표 속성: width, headwidth, headlength, shrink
2. 2중 y축 표기
- fig, ax1 = plt.subplots()
ax1.plot(x, y)
ax2 = ax1.twinx(): x축을 공유하는 새로운 객체를 만든다.
ax2.plot(x, y)
- ax1, ax2등으로 각각의 축이나 그래프에 접근하여 따로 옵션 설정 가능
fig, ax1 = plt.subplots()
ax1.bar(age, height, color = 'skyblue', width = 0.5, ec = 'lightgray', label = 'height')
ax2 = ax1.twinx()
ax2.plot(age, weight, color = 'darkred', marker = 'o', ls = '--', label = 'weight')
ax1.set_xlabel('나이')
ax1.set_ylabel('키(cm)')
ax2.set_ylabel('몸무게(kg)')
ax1.set_ylim(150, 180)
ax2.set_ylim(60, 90)
ax1.set_yticks(height)
ax2.set_yticks(weight)
ax1.tick_params(axis = 'y', colors = 'skyblue')
ax2.tick_params(axis = 'y', colors = 'darkred')
ax1.legend()
ax2.legend()
ax1.grid(axis = 'y', ls = '--', color = 'skyblue')
ax2.grid(axis = 'y', ls = '--', color = 'pink')
plt.show()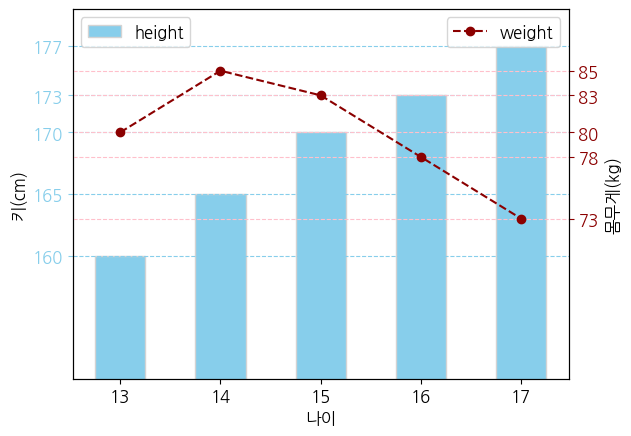
3. Seaborn으로 그래프 그리기
3.1 바그래프
- seaborn은 그룹화를 통한 평균이나 통계적 연산을 자동으로 수행하여 그래프로 그려줌
- sns.barplot(x, y, data): x축 데이터로 그룹화한 y축 데이터의 평균을 계산하여 그래프를 그림
estimator = 통계함수: 옵션을 지정하여 지정한 연산을 수행한 결과를 그래프로 번환
hue: y를 그룹화할 칼럼을 추가적으로 지정해줄 수 있음
- ci = None: 신뢰구간을 표시하지 않음
sns.barplot(data = tips, x = 'day', y = 'tip', ci = None, estimator = sum, hue = 'smoker',
palette = {'Yes': 'gray', 'No': 'skyblue'})
plt.title('요일별 팁 합계', size = 15)
plt.grid(axis = 'y', ls = ':')
plt.show()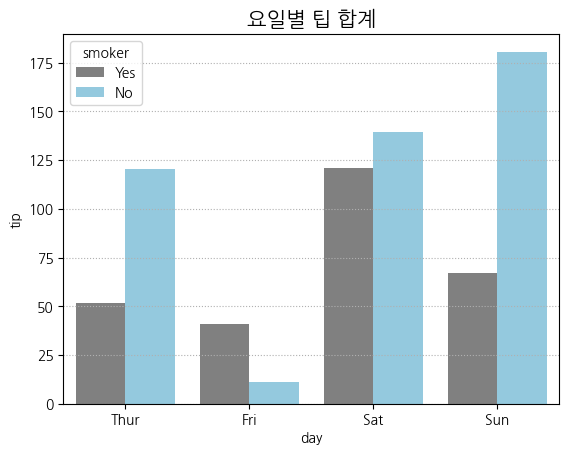
3,2 산점도
- sns.scatterplot(x, y, data)
- hue를 통한 특정 그룹별 색상 지정, size를 통한 원의 크기 지정이 가능함
3.3 선그래프
- sns.lineplot(data=데이터프레임, x=x축컬럼, y=y축컬럼, estimator=통계함수)
estimator를 생략하면 평균으로 통계를 적용함
3.4 카운트플롯
- 데이터의 갯수를 카운트하여 시각화
- sns.countplot(x, data)
3.5 러그플롯
- sns.rugplot(x, data)
- 데이터의 종류가 많지 않을 때, 데이터가 어디에 분포하는지 등을 확인하기 위해 사용
3.6 히스토그램
- sns.displot(x, data)
- bins:구간의 개수, rug = True: 러그 표시의 유무, kde = True: 커널밀도추정 표시 유무
kind = 'kde': 막대대신 커널밀도추정만 표시, hue를 통한 그룹화 옵션 지정 가능
sns.displot(data = iris, x = 'petal_length', bins = 20, rug = True, hue = 'species', kde = True)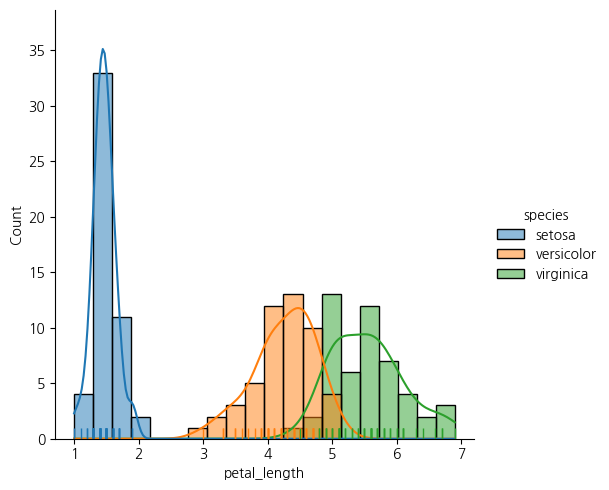
3.7 박스플롯, 바이올린플롯, 스트립플롯, 스웜플롯
- sns.boxplot(data=데이터프레임)
- sns.violinplot(data=데이터프레임)
- sns.stripplot(data=데이터프레임)
- sns.swarmplot(data=데이터프레임)
plt.figure(figsize=(12,8))
plt.subplot(221)
sns.boxplot(data = iris)
plt.subplot(222)
sns.violinplot(data = iris)
plt.subplot(223)
sns.stripplot(data = iris)
plt.subplot(224)
sns.swarmplot(data = iris, s = 3)
plt.show()
4. 데이터 시각화 활용
4.1 서울시 연간 평균기온, 최저기온, 최고기온 비교
전국의 일자별 평균기온, 최저기온, 최고기온 정보를 담은 데이터셋을 활용해서 서울시의 연간 평균기온, 최저기온, 최고기온을 그래프를 통해 비교해보고자 한다. 먼저 서울시의 정보를 추출하고, 연간 일 평균기온, 연간 최저기온, 연간 최고기온을 나타내는 데이터셋을 생성했다.
#서울시 데이터만 추출
df_seoul = df[df['지점명'] == '서울'].copy()
#연간 평균기온 데이터
df_seoul_mean = df_seoul.groupby([df_seoul['일시'].dt.year)['평균기온(°C)'].mean()
#연간 최저기온 데이터
df_seoul_min = df_seoul.groupby(df_seoul['일시'].dt.year)['최저기온(°C)'].min()
#연간 최고기온 데이터
df_seoul_max = df_seoul.groupby(df_seoul['일시'].dt.year)['최고기온(°C)'].max()
서브플롯을 통해 서울시의 연간 평균기온, 최저기온, 최고기온을 나타내는 그래프를 나눠서 그릴 수 있다.
fig = plt.figure(figsize = (15, 5))
plt.subplot(131)
plt.plot(df_seoul_mean, 'g.-')
plt.title('서울시 연 평균기온의 변화', size = 15)
plt.xlabel('연도')
plt.ylabel('평균기온')
plt.grid(ls = ':')
plt.subplot(132)
plt.plot(df_seoul_min, marker = 'o', color = 'orange', ls = ':', markersize = 5)
plt.title('서울시 연 최저기온의 변화', size = 15)
plt.xlabel('연도')
plt.ylabel('최저기온')
plt.grid(ls = ':')
plt.subplot(133)
plt.plot(df_seoul_max, marker = 'o', color = 'red', ls = '-', markersize = 5)
plt.title('서울시 연 최고기온의 변화', size = 15)
plt.xlabel('연도')
plt.ylabel('최고기온')
plt.grid(ls = ':')
fig.suptitle('서울시 기온 변화', size = 20, fontweight = 'bold')
fig.tight_layout()
plt.show()
시각화를 통해 서울시의 연 평균기온과 최저기온이 시간의 흐름에 따라 점차 증가하고 있다는 것을 확인할 수 있다. 겨울이 점점 따뜻해지고 있다는 의미로 해석할 수 있을 것이다. 반면 최고기온은 증가했다가 다시 감소했다가를 반복하는 모습을 보이며, 최근에는 최고기온이 증가하는 추세를 보이고 있다.
4.2 2020년 전국의 지점별 기온 비교
2020년 전국의 지점별 평균기온, 최저기온, 최고기온 정보를 담은 데이터셋을 활용해서 온도가 평균적으로 높은 지점, 낮은 지점, 그리고 서울의 기온은 어떤지 살펴보았다. 먼저 전체 데이터셋에서 2020년 데이터를 추출하고, 지점별 평균기온, 최저기온, 최고기온을 나타내는 데이터셋을 생성했다. 여기에는 그 중 하나인 평균기온 비교만 수록한다.
#2020년 기온 데이터 추출
df_2020 = df[df['일시'].dt.year == 2020].copy()
#지점별 연간 일 평균기온 데이터 생성
df_2020_mean = df_2020.groupby('지점명')['평균기온(°C)'].mean().sort_values(ascending = False)
위 데이터셋으로 지점을 x축으로, 평균기온을 y축으로 하는 바그래프를 그릴 수 있다. 바그래프를 그리고 지점별 평균기온 중 최저기온, 평균기온, 최고기온을 찾아 수평선으로 표기하고, 서울의 바그래프를 따로 표시하였다. 그 결과는 다음과 같다.
# 지점별 연 평균기온
plt.figure(figsize = (20, 5))
plt.bar(df_2020_mean.index, df_2020_mean, color = 'lightgreen')
plt.title('2020년의 지점별 연 평균기온', size = 20, pad = 10)
plt.xticks(rotation = 90)
# 최고, 평균, 최저 라인 표시
plt.axhline(df_2020_mean.min(), color = 'b', ls = ':', label ='최저' + str(round(df_2020_mean.min(),1)))
plt.axhline(df_2020_mean.mean(), color = 'g', ls = ':', label = '평균'+ str(round(df_2020_mean.mean(),1)))
plt.axhline(df_2020_mean.max(), color = 'r', ls = ':', label = '최고'+ str(round(df_2020_mean.max(),1)))
plt.legend(loc=(0.01, 1.01), ncol = 3, fontsize = 12)
# 서울지역 표시
plt.bar('서울', df_2020_mean.loc['서울'], color = 'green')
plt.text('서울', df_2020_mean.loc['서울'] + 0.5, '서울 (' + str(round(df_2020_mean.loc['서울'],1))+')', ha = 'center', fontsize = 15)
plt.show()
초반부분과 끝부분은 계단식으로 차이가 크게 존재함을 확인할 수 있고, 그 이외의 지역은 차이가 완만하게 존재하는 것으로 보인다. 제주도의 평균기온이 가장 높으며, 대관령이 유독 평균기온이 낮은 것을 확인할 수 있다. 서울은 전체 지역중 평균적인 온도를 가짐을 확인할 수 있다.
가장 평균기온이 높았던 서귀포, 가장 평균기온이 낮았던 대관령, 그리고 평균적인 온도를 보인 서울을 기준으로 일 평균기온의 분포를 시각화해보았다.
# 스타일 파라미터
plt.rcParams['hatch.color'] = 'w'
# 서브플롯 만들기(plt.subplots())
fig, ax = plt.subplots(1, 3, figsize = (15, 5), sharex = True)
# 서귀포 일평균기온 히스토그램
ax[0].hist(df_2020_sgp['평균기온(°C)'], rwidth = 0.9, hatch = '//')
ax[0].set_title('2020s년 서귀포의 평균기온 분포')
ax[0].set_xlabel('일 평균기온')
ax[0].set_xlabel('일수')
# 서울 일평균기온 히스토그램
ax[1].hist(df_2020_seoul['평균기온(°C)'], rwidth = 0.9, hatch = '--')
ax[1].set_title('2020년 서울의 평균기온 분포')
ax[1].set_xlabel('일 평균기온')
ax[1].set_xlabel('일수')
# 대관령
ax[2].hist(df_2020_dgr['평균기온(°C)'], rwidth = 0.9, hatch = 'xx')
ax[2].set_title('2020년 대관령의 평균기온 분포')
ax[2].set_xlabel('일 평균기온')
ax[2].set_xlabel('일수')
# 0°C 수직선 표시
ax[0].axvline(0, color ='k', ls = '--')
ax[1].axvline(0, color ='k', ls = '--')
ax[2].axvline(0, color ='k', ls = '--')
plt.tight_layout()
plt.show()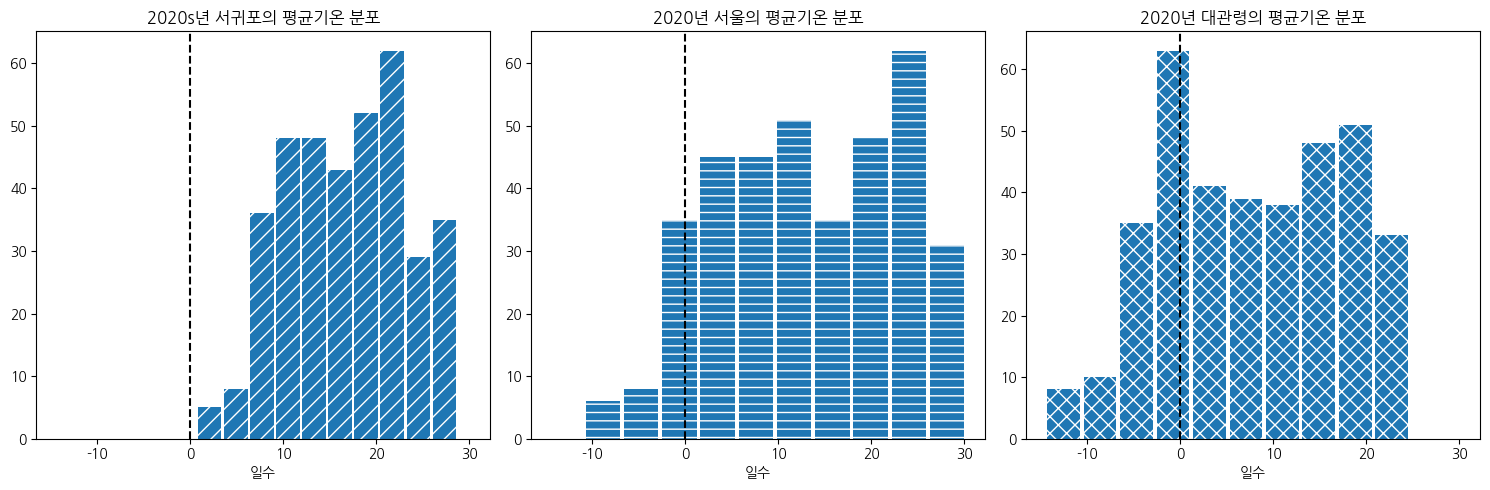
서귀포의 평균기온은 0도 이하로 내려간 날은 없으며, 온도가 낮은 날은 확연히 적고 보통 20도대로 분포하여 전국에서 날씨가 가장 온화한 곳임을 추측할 수 있다. 반면, 서울은 서귀포와 다르게 일 평균기온이 영하까지 내려가는 날도 존재하며, 평균기온이 25도정도일때의 날이 가장 많고, 30도 이상의 매우 더운 날들도 존재한다. 대관령은 평균적으로 기온이 낮으며 0도 미만으로 떨어지는 날들이 서울에 비해서도 많이 존재하고, 기온이 높은 날들은 상대적으로 적어 전국에서 가장 추운 지역임을 짐작할 수 있다.
소감 및 정리
평소 그래프를 그릴 때는 단순히 데이터 확인용으로만 많이 사용해서 그래프 옵션을 거의 사용하지 않았다. 실습을 통해 그래프를 다양하게 꾸밀 수 있는 방식들과, 그래프에 옵션들을 추가함으로써 보여주고자 하는 바를 더 명확하게 표현할 수 있고 해석도 쉬워진다는 것을 깨달았다. 앞으로 이번에 배운 옵션들을 다양하게 사용하여 더 가독성 좋은 그래프를 만들 수 있도록 노력해야겠다는 생각이 들었다.
'STARTERS > TIL' 카테고리의 다른 글
| [TIL] 8일차 TIL(20230215) - DBMS이론 및 SQL기초, 조건절 (0) | 2023.02.15 |
|---|---|
| [TIL] 7일차 TIL(20230214) - 데이터 전처리 및 다중막대그래프 (0) | 2023.02.14 |
| [TIL] 5일차 TIL(20230210) - Matplotlib를 이용한 데이터 시각화 (0) | 2023.02.10 |
| [TIL] 4일차 TIL(20230209) - 데이터 시각화, 서울시 물가정보 분석 (1) | 2023.02.09 |
| [TIL] 3일차 TIL(20230208) - 데이터프레임, 전처리 (0) | 2023.02.08 |



