
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- python
- 취업부트캠프
- 유데미코리아
- 태블로
- 파이썬
- 코딩테스트
- 스타터스부트캠프
- 백준
- 데이터드리븐
- 데이터프레임
- Leetcode
- numpy
- 유데미큐레이션
- 데이터시각화
- Til
- 부트캠프후기
- 데이터분석
- 그리디 알고리즘
- DataFrame
- 시각화
- Tableau
- 유데미
- 정렬
- matplotlb
- 브루트포스 알고리즘
- pandas
- 넘파이
- ndarray
- 판다스
- 유데미부트캠프
- Today
- Total
Diary, Data, IT
[TIL] 50일차 TIL(20230417) - SQL 고객분석 본문

[TIL] 50일차 TIL(20230417) - SQL 고객분석
📗 고객 분석
✅ 국가별 고객 수, 누적 합계
- 고객 수로 내림차순 정렬하되, 고객 수가 동일한 경우 국가명으로 오름차순 정렬
SELECT *, sum(고객수) over(ORDER BY 고객수 DESC, country) 누적합계
FROM (SELECT country, count(country) 고객수
FROM customers
GROUP BY country
ORDER BY count(country) desc, country) c1sum(고객수) over(order by 고객수 desc, country)를 통해서 구할 수 있었는데, order by는 어떤 기준으로 집계할 것인지에 대한 의미와 어떤 순서로 집계할 것인지에 대한 내용까지 내포하고 있어 올바른 순서와 기준으로 집계하기 위해 조건에 관련된 내용을 모두 넣어주어야 한다.
✅ 국가별 고객 수, 구성비, 누적구성비
- 고객 수로 내림차순 정렬하되, 고객 수가 동일한 경우 국가명으로 오름차순 정렬
SELECT *,
sum(구성비) OVER(ORDER BY 고객수 DESC, country) 누적구성비
FROM (SELECT country, count(country) 고객수, count(country)/sum(count(country)) over() * 100 구성비
FROM customers
GROUP BY country
ORDER BY count(country) desc, country) c1
✅ 구매 이력이 없는 고객
- NOT IN: 주문한 고객 리스트를 서브쿼리로 만들어서, 전체 고객 내역 중 주문 고객 내역에 없는 고객만 추출
- 차집합: 차집합을 이용해 전체 고객 리스트에서 주문 내역에 있는 고객을 제거
- left join: 전체 고객 리스트를 기준으로 주문 고객 리스트를 left join하여 전체 고객 중 주문을 하지 않은 고객은 주문 관련 컬럼들이 NULL로 나오도록 만든다. 그 후 NULL인 customer_id를 찾아주면 된다.
-- NOT IN
SELECT c.customer_id, c.company_name
FROM customers c
WHERE c.customer_id NOT IN (SELECT DISTINCT customer_id FROM orders);
-- 차집합
SELECT c.customer_id FROM customers c
EXCEPT
SELECT o.customer_id FROM orders o;
-- left join
SELECT c.customer_id, c.company_name FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_id IS NULL;
✅ 고객분석 기본 테이블
고객분석에 필요한 모든 컬럼들을 담은 하나의 기본 테이블을 생성하여, 이후부터는 이 기본 테이블을 바탕으로 분석을 진행했다.
WITH cte_customers as(
SELECT c.customer_id, c.company_name, c.contact_title, c.country, c.city,
o.order_id, o.order_date,
to_char(o.order_date, 'YYYY') AS year,
to_char(o.order_date, 'MM') AS month,
to_char(o.order_date, 'DD') AS day,
to_char(o.order_date, 'Q') AS quarter,
date_part('dow', o.order_date) dow,
od.product_id, od.unit_price, od.quantity, od.discount,
od.unit_price * od.quantity * (1-od.discount) amount,
p.product_name, c2.category_id, c2.category_name
FROM customers c, orders o, order_details od, products p, categories c2
WHERE c.customer_id = o.customer_id AND o.order_id = od.order_id AND
od.product_id = p.product_id AND p.category_id = c2.category_id
)
✅ 국가별 고객수, 매출액, 주문건수 집계
SELECT country, count(DISTINCT customer_id) 고객수, sum(amount) 매출액, count(DISTINCT order_id) 주문건수
FROM cte_customers
GROUP BY country
ORDER BY 3 desc
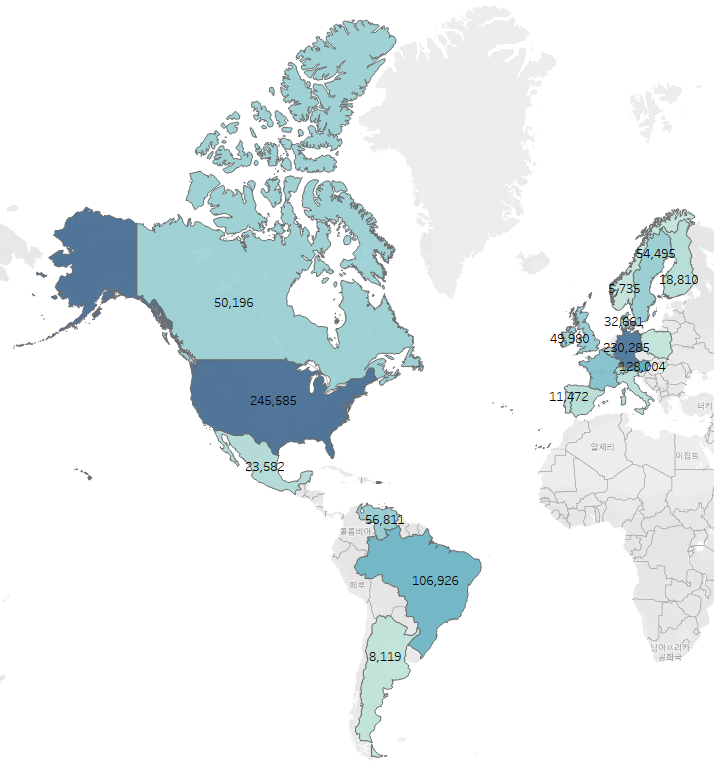
✅ 국가별 고객수, 매출액, 주문건수의 상관계수
SELECT corr(고객수, 매출액) corr_고객수_매출액,
corr(매출액, 주문건수) corr_매출액_주문건수,
corr(고객수, 주문건수) corr_고객수_주문건수
FROM country_customers_table
✅ 대륙별 고객수, 매출액, 주문건수 집계
-- 대륙 컬럼 생성
cte_country_group AS (
SELECT *,
CASE
WHEN lower(country) in ('usa', 'canada', 'mexico') THEN 'NorthAmerica'
WHEN lower(country) IN ('brazil', 'venezuela', 'argentina') THEN 'SouthAmerica'
ELSE 'Europe'
END AS 지역
FROM country_customers_table
),
-- 대륙별 집계
SELECT 지역, sum(고객수) 고객수, sum(매출액) 매출액, sum(주문건수) 주문건수
FROM cte_country_group
GROUP BY 지역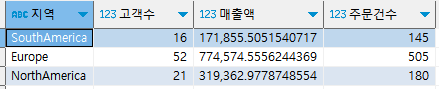
✅ 대륙별 고객수, 매출액, 주문건수의 구성비
group by에 고객수, 매출액, 주문건수를 넣어주는 이유는 group by에 포함된 컬럼만 명시할 수 있기 때문이다. 또한 해당 컬럼들은 이미 집계된 결과이므로 group by에 넣어도 값의 차이가 발생하지는 않는다.
SELECT 지역, 고객수, round((sum(고객수)/sum(고객수) over()) * 100) 고객수구성비,
매출액, round((sum(매출액)/sum(매출액) over()) * 100) 매출액구성비,
주문건수, round((sum(주문건수)/sum(주문건수) over()) * 100) 주문건수구성비
FROM cte_continent_customer_table
GROUP BY 지역, 고객수, 매출액, 주문건수
✅ 대륙별 판매수량 순위를 기준으로 제품명 나열
대륙을 컬럼으로 하여 rank에 해당하는 제품명을 나열하는 테이블을 생성했다.
case ~ when을 사용하여 각 대륙과 순위에 해당하는 product_info를 보여주는 방식을 사용했다.
-- 대륙별 상품의 판매수량
cte_continent_quantity AS (
SELECT '[' || category_name || ']' || product_name || '(' || product_id || ')' product_info,
CASE
WHEN lower(country) in ('usa', 'canada', 'mexico') THEN 'NorthAmerica'
WHEN lower(country) IN ('brazil', 'venezuela', 'argentina') THEN 'SouthAmerica'
ELSE 'Europe'
END AS 지역,
sum(quantity) 판매수량
FROM cte_customers
GROUP BY 지역, 1
),
-- 대륙별 판매수량 순위
cte_continent_quantity_rank AS (
SELECT *, row_number() over(PARTITION BY 지역 ORDER BY 판매수량 DESC) rnk
FROM cte_continent_quantity
)
-- 대륙별 제품순위 pivot
SELECT rnk,
max(CASE WHEN 지역 = 'NorthAmerica' THEN product_info END) AS "North America",
max(CASE WHEN 지역 = 'SouthAmerica' THEN product_info END) AS "South America",
max(CASE WHEN 지역 = 'Europe' THEN product_info END) AS "Europe"
FROM cte_continent_quantity_rank
GROUP BY 1
ORDER BY 1
✅ 고객별 매출액, 주문건수, 건당평균주문액과 순위
이번에는 지역/대륙별이 아니라 고객별로 테이블을 구성했다.
각 지표와 순위를 함께 사용하기 위해 rank() 함수를 사용했고, 하나의 쿼리문에 같이 작성하여 여러번 집계하는 불편함을 줄였다.
SELECT customer_id, count(DISTINCT order_id) 주문건수,
RANK() OVER(ORDER BY count(DISTINCT order_id) DESC) 주문건수순위,
sum(amount) 매출액,
RANK() OVER(ORDER BY sum(amount) DESC) 매출액순위,
sum(amount) / count(DISTINCT order_id) 건당평균주문액,
RANK() OVER(ORDER BY sum(amount) / count(DISTINCT order_id) DESC) 건당평균주문액순위
FROM cte_customers
GROUP BY customer_id
ORDER BY 5
✅ 전체 고객별 매출액, 주문건수, 건당평균주문액과 순위
left join을 이용해 주문을 하지 않은 고객도 리스트에 포함할 수 있도록 구성하였다.
주의할 점은 desc로 내림차순 정렬하게 되면 NULL이 가장 상단에 위치하게 된다는 점이다.
따라서 rank함수를 사용할 경우 NULL이 1등이 된다.
이를 방지하고, 여기서 NULL이란 결국 매출액, 주문건수가 0이라는 것을 의미하므로 coalesce를 사용해 0으로 대체했다.
WITH cte_customers as(
SELECT c.customer_id, c.company_name, c.contact_title, c.country, c.city,
o.order_id, o.order_date,
to_char(o.order_date, 'YYYY') AS year,
to_char(o.order_date, 'MM') AS month,
to_char(o.order_date, 'DD') AS day,
to_char(o.order_date, 'Q') AS quarter,
date_part('dow', o.order_date) dow,
od.product_id, od.unit_price, od.quantity, od.discount,
od.unit_price * od.quantity * (1-od.discount) amount,
p.product_name, c2.category_id, c2.category_name
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id
LEFT JOIN order_details od ON o.order_id = od.order_id
LEFT JOIN products p ON p.product_id = od.product_id
LEFT JOIN categories c2 ON c2.category_id = p.category_id
)
SELECT customer_id, count(DISTINCT order_id) 주문건수,
RANK() OVER(ORDER BY count(DISTINCT order_id) DESC) 주문건수순위,
COALESCE(sum(amount), 0) 매출액,
RANK() OVER(ORDER BY COALESCE(sum(amount), 0) DESC) 매출액순위,
COALESCE(sum(amount) / count(DISTINCT order_id), 0) 건당평균주문액,
RANK() OVER(ORDER BY COALESCE(sum(amount) / count(DISTINCT order_id), 0) DESC) 건당평균주문액순위
FROM cte_customers
GROUP BY customer_id
ORDER BY 5;
📗 Decil 분석
✅ 분석 방법
1. 고객의 총 매출액 기준으로 정렬하고, 상위부터 10%씩 나누어 10개의 그룹을 할당한다.
2. decil별 매출합계, decil별 구성비, decil별 구성비 누계를 확인한다.
각각의 그룹으로 나눈 뒤 현황을 살펴, 그룹별 전략을 다르게 세우는 등 활용할 수 있다.
고객을 10개의 그룹으로 나누기 위해 ntile함수를 사용했다.
ntile(나눌 group 수) over(partition by ~ order by ~)
-- 고객별 매출액을 기준으로 decil 생성
customers_amount_decil AS (
SELECT customer_id, sum(amount) amount, ntile(10) over(ORDER BY sum(amount) desc) decil
FROM cte_customers
GROUP BY customer_id
ORDER BY 2 DESC
),
-- decil별 매출합계, 구성비, 구성비 누계
customers_amount_decil2 AS (
SELECT decil,
sum(amount) amount,
sum(amount) / sum(sum(amount)) over() * 100 amount_rate
FROM customers_amount_decil
GROUP BY decil
)
SELECT *,
sum(amount_rate) over(ORDER BY decil) cummulative_amount
FROM customers_amount_decil2
✅ Decil 분석의 문제점
- 한번의 구매로 비싼 물건을 구매한 사용자와 정기적으로 저렴한 물건을 여러번 구매한 사용자가 같은 그룹으로 판정되는 문제
- 검색기간이 너무 장기간이면 과거에는 우수고객이었어도 현재는 다른 서비스를 사용하는 휴면고객이 포함될 수 있음
- 검색기간이 너무 단기간이면 정기적으로 구매하는 안정고객보다 해당 기간동안 일시적으로 많이 구매한 사용자가 우수고객으로 포함될 수 있음
📗 RFM 분석
✅ 분석 개요
- 구매 가능성이 높은 고객을 식별하기 위한 데이터 분석 방법
- 마케팅에서 사용자 타겟팅을 위한 방법
- Recency: 얼마나 최근에 구매했는가? (최근에 구매한 고객이 추후 구매 확률이 더 높다고 가정)
- Frequency: 얼마나 빈번하게 구매했는가?
- Monetary: 얼마나 많은 금액을 지불했는가?
- R > F > M 순으로 비중을 둔다.
- 집계 기간을 어떻게 설정할 것인지 고려할 필요가 있다.
SELECT customer_id, max(order_date) - max(max(order_date)) over() recency,
count(DISTINCT order_id) frequency, sum(amount) monetary
FROM cte_customers
GROUP BY customer_id
ORDER BY recency desc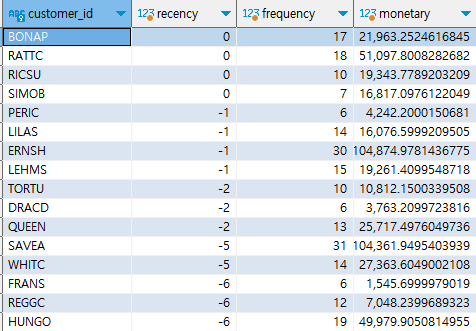
📗 고객 대상 ABC분석 (과제)
기존에 상품을 대상으로 진행했던 ABC분석을 고객을 기준으로하여 다시 수행했다. 코드 및 시각화 결과는 다음과 같다.
WITH cte_customers as(
SELECT c.customer_id, c.company_name, c.contact_title, c.country, c.city,
o.order_id, o.order_date,
to_char(o.order_date, 'YYYY') AS year,
to_char(o.order_date, 'MM') AS month,
to_char(o.order_date, 'DD') AS day,
to_char(o.order_date, 'Q') AS quarter,
date_part('dow', o.order_date) dow,
od.product_id, od.unit_price, od.quantity, od.discount,
od.unit_price * od.quantity * (1-od.discount) amount,
p.product_name, c2.category_id, c2.category_name
FROM customers c, orders o, order_details od, products p, categories c2
WHERE c.customer_id = o.customer_id AND o.order_id = od.order_id AND
od.product_id = p.product_id AND p.category_id = c2.category_id
),
-- 매출액이 많은 순으로 정렬, 총 매출액 대비 고객별 매출액의 비율
customer_amount_ratio AS (
SELECT customer_id, company_name, sum(amount) amount,
sum(amount) / sum(sum(amount)) over() * 100 amount_ratio
FROM cte_customers
GROUP BY 1, 2
ORDER BY 3 DESC
),
-- 구성비율이 높은 고객부터 정렬한 누적 비율
customer_amount_ratio2 AS (
SELECT *,
sum(amount_ratio) over(ORDER BY amount_ratio desc) cummulative_amount_ratio
FROM customer_amount_ratio
)
-- 그룹 정의 ~70%: A, ~ 90%: B, 이 외 C그룹
SELECT *,
CASE
WHEN cummulative_amount_ratio <= 70 THEN 'A'
WHEN cummulative_amount_ratio <= 90 THEN 'B'
ELSE 'C'
END AS group
FROM customer_amount_ratio2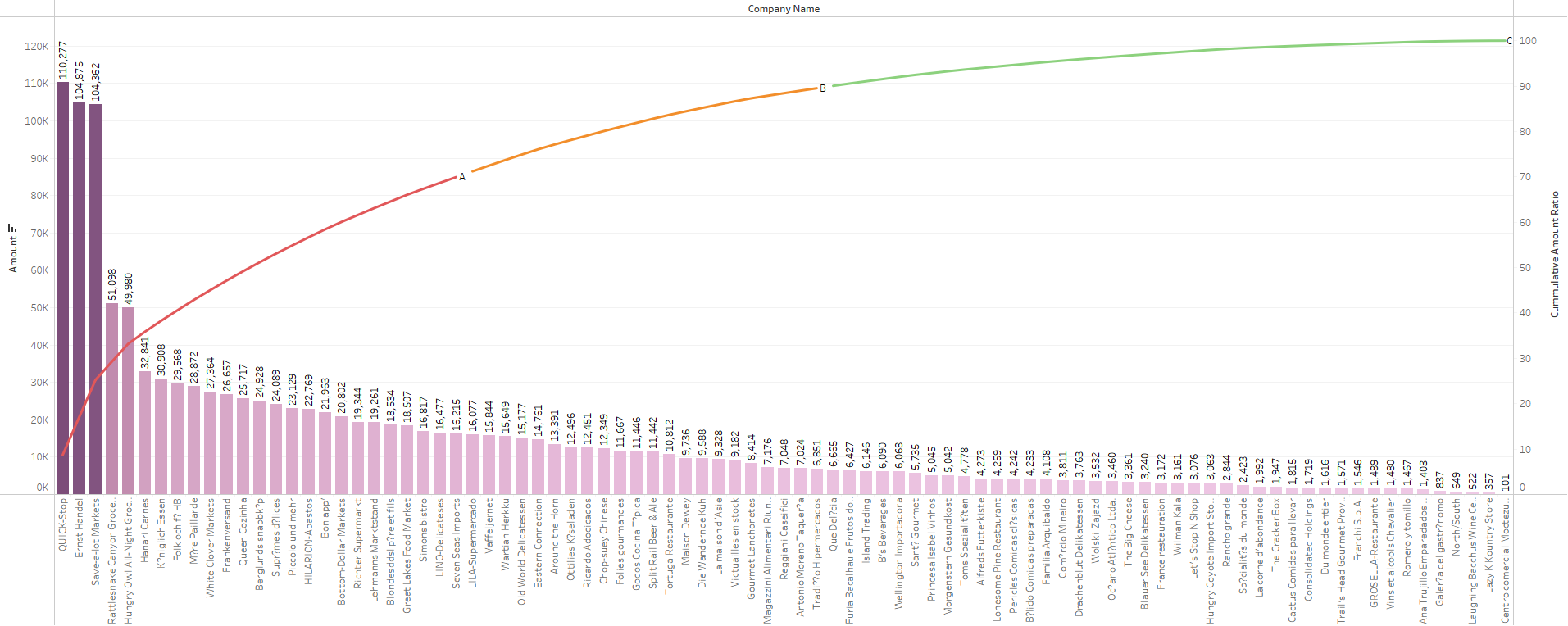
소감 및 정리
오늘은 여러 예제들을 바탕으로 다양한 고객분석과 관련된 지표들을 뽑아보고 decil분석까지 수행했다. 고객분석을 수행하면서 대부분의 쿼리에 모두 집계함수가 사용되었다. 비율을 구하거나 누적하거나 순위를 구하거나 하는 작업이 자주 필요했는데 이제는 이런 작업에 partition by와 order by를 적절하게 사용할 수 있게 된 것 같다. 또 left join이나 IN 같은 기초 쿼리문에서 다뤘지만 최근에는 사용하지 않았던 함수들까지 사용했는데 이렇게 다른 여러 예제들을 만들어가면서 다양한 함수들을 골고루 사용할 필요가 있을 것 같다. 잊어버리지 않도록!🙄
'STARTERS > TIL' 카테고리의 다른 글
| [TIL] 52일차 TIL(20230419) - SQL 미니 프로젝트 (0) | 2023.04.19 |
|---|---|
| [TIL] 51일차 TIL(20230418) - SQL RFM 분석, 재구매율, 이탈률 분석 (0) | 2023.04.18 |
| [TIL] 49일차 TIL(20230414) - SQL Z차트, 그룹함수(grouping sets, roll up) (0) | 2023.04.14 |
| [TIL] 48일차 TIL(20230413) - SQL 제품/카테고리 매출 지표 분석, PIVOT (0) | 2023.04.13 |
| [TIL] 47일차 TIL(20230412) - SQL CTE, WINDOW 함수 (0) | 2023.04.12 |



